本稿は、インターネット上のホームページ作成言語として知られるHTML(Hyper Text Markup Language)が新しい知的資産の形成にきわめて有効であることを論じることを目的とする。また、現時点においてインターネットを研究活動に利用する上での問題点についても指摘することにしたい。
近年、パソコンの低価格化とプロバイダの多角化によって、研究機関や公共団体や企業はもとより、一般家庭でも電話回線を通じてインターネット上のホームページを自由に見ることができるようになった。そして、単に受け身的に情報の網を渉猟するだけでなく、みずからホームページを開設し、研究機関であれば学術情報を、公共団体であれば生活情報を、個人であれば家族の紹介や自分の趣味にかかわる情報などを提供しようという動きが飛躍的に増大しつつある。HTMLは、そうしたホームページを作成するために利用される代表的言語である。部分的に別の特殊な言語を利用することはあるが、文字や画像からなるページの基本部分は、まず例外なくHTML言語で記述されていると断言しても過言ではないだろう。
しかし、入門書などでは、インターネットとの結びつきばかりが強調される傾向がある。最近出版された関連書籍のタイトルをNACSISの和書検索システムで追ってみても、『インターネットホームページデザイン:インターネットエンジェルたちのためのWWW/HTML』、『HTML入門:WWWページの作成と公開』、『HTMLでクールなWebページを作ろう』...というように、ホームページの作成の手段としてのHTMLという側面がアピールされている。そこで本稿では、HTMLがインターネットとは無関係の部分で知的資産の形成にいかに有効であるかという点を強調していくことにしたい。
まずHTML自体にふれる前に、HTMLが、インターネットやWWWやホームページとどういう関係にあるのか明確にしておこう。
インターネットとは、冷戦時代のアメリカで、核攻撃によって中途の通信回線が破壊されても、生き残った回線を利用して最も効率のよい経路で目的地まで情報を伝えることのできるシステムとして開発された。しかし現在では、むしろ学術目的の情報交換や商用に利用されている。岡山大学の場合は、建物の天井に張り巡らされたイーサネットケーブルをパソコンの専用ボードに繋ぎ、IPアドレスを取得し、所定のソフトを起動することによって、学内LAN(Local Area Network)からSINET経由でインターネットを利用することができる。電話回線を経由しないので、接続時間に応じて電話代を支払う必要は全くない。また、大型計算機も経由しないし、特定のプロバイダと契約する必要もないので、1日中利用したからといって研究費から何らかの課金が差し引かれるというようなことはない(裏を返せば、その利用形態はひとえに研究者の良識に委ねられているということになる)。いっぽう、定期保守作業や事故のためLANサーバやSINETが停止すると学外には一切接続ができなくなる点が、電話回線利用の場合と異なる。
次に、WWW(World Wide Web)とはインターネット上の情報公開システムのことで、これを介して後述するHTML文書を読んだり、画像を眺めたり音声を聞くことができる。このシステム上で稼働する情報探索用のソフトウェアはWWWブラウザと呼ばれ、代表的なものとしては、Netscape Communications社のネットスケープ・ナビゲータ、Microsoft社のインターネット・エクスプローラなどが知られている。“WWW”は、“ウェブ”、“ダブリュー・スリー”、“ダブダブダブ”などと発音されるが正式の呼び方は特に定まっていないようである。インターネットでは、WWWのほか、Telnet、FTP、Gopher、電子メイル、ネットニュースなどのサービスを利用することができる。但し、それらは全くの別物というわけではなく、最新のWWWブラウザを利用すれば、大概のやりとりができるようになっている。
もうひとつ、ホームページ(Home Page)とは、WWW上の情報発信拠点となるファイルの(集合体)のことを言う。ファイルには、文書を文字列だけで表したテキストファイル、写真やグラフを表す画像ファイル、声や音楽を録音した音声ファイル、ビデオやアニメなどの動画ファイルなどさまざまなファイルがある。文書以外のファイルを単独で表示することもできるが、通常は文書に貼り付けられたものを説明文とともに参照することになる。HTMLで書かれたハイパーテキストファイルは、このような文書や画像をWWW上で最も効率的に表示するための基本をなすファイルである。
次に簡単なHTMLを例示しておこう。HTMLとは、“Hyper Text Markup Language”の略であり、しいて和訳すれば“ハイパーテキスト・マーク付言語”ということになる。考案者は、Tim Beerners-Lee氏で、現在ではCNRI(The Corporation for National Research Initiatives)という非営利団体が中心となって開発を担っている(Sachi, 1995)。コンピュータの言語というとC言語やLispのような難解な言語を想像しがちであるが、実際にはテキストファイル(文字列だけのファイル)の一部にtagと呼ばれる修飾記号を挿入したようなもので、パソコンのワープロソフトを使いこなせる者であれば容易に修得できるごく簡単なルールから成り立っている。
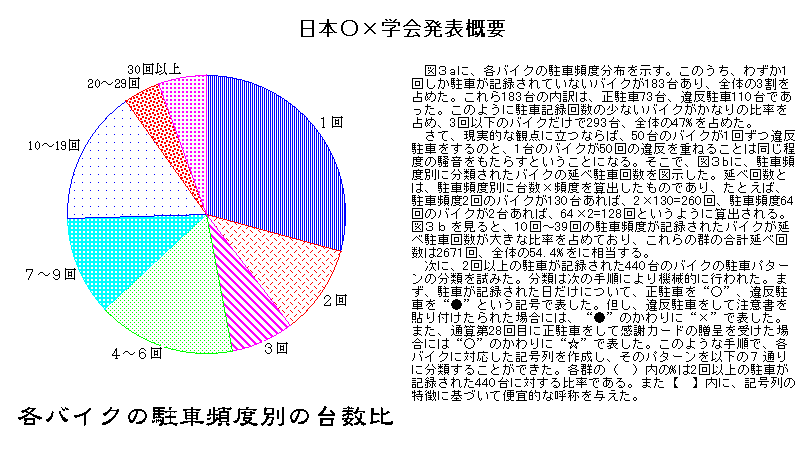
例えば、図1のような“発表概要”をHTMLで作成するには、表1のようなテキスト文書を、ワープロやエディタで作ればよい。
図1 |
|
<HTML>
<BODY> <center><h2>日本○×学会発表概要</h2></center> <IMG SRC="Fig3a.gif" align="left"> <BR>図3aに、各バイクの駐車頻度分布を示す。...【中途略】...全体の47%を占めた。 <BR>さて、現実的な観点に立つならば...【中途略】...全体の54.4%をに相当する。 <BR>次に、...【中途略】...便宜的な呼称を与えた。 </BODY> </HTML> |
要するに、テキストファイルと異なる点は、HTMLファイルの文頭に <HTML><HEAD> ファイルの文末に、 </BODY></HTML> というように、始まりを示す< >と、終わりを示す</ >という、タグ(tag)がつけられていることにある。つまり、文書だけをテキストファイルからHTMLファイルに変換するのであれば、文頭と文末にこれらのタグを付加すれば事足りる。なお、これらのタグがつかないテキストファイルをブラウザで読み込むこともできるが、ウィンドウズ窓の右端での折り返し機能が働かなくなるため、1段落が1行となり、長大な横並びの文字列が窓の枠内に入るところだけ部分的に表示されてしまうようになる。
このほか、表1では、タイトルをセンタリングするための<center>...</center>、文字を大きめにするための<h2>...</h2>、改行を入れるための<BR>が付加されている。もうひとつ、グラフの表示を指示する<IMG SRC="Fig3a.gif" align="left"> というタグがある。グラフを表示するためには、作図ソフトなどで作成した画像を文書ファイルとは別ファイル(図1の例では“Fig3a.gif”)として保管しておく必要がある。
テキスト文書が容易にHTML文書に変換できることは上に述べたとおりであるが、文字を修飾したりいろいろにレイアウトを施したワープロ文書とHTML文書はどこが違っているのだろうか?
第1に、それを読む手段が異なる。ワープロ文書は、ワープロソフトを起動して眺めることもできるが、最終的には紙に印刷して読む。一方、HTML文書は、パソコンからWWWブラウザソフトを起動して読む。その内容を紙に印刷することもできるが、それでは後述するようなハイパーテキストの良さを活かすことができない。
第2に、HTML文書ではレイアウトが可塑的になる。ワープロを用いて印刷された文書は、レイアウトが決して変わることがない。縮小や拡大コピーをとることでサイズを変えられる程度である。いっぽう、HTML文書は、読み手側のブラウザの設定によって見え方がかなり変化する。例えば、読み手がブラウザの窓を横長に設定していた場合、図1と同じ文書は図2aのように表示され、文章全体がグラフの右側に配置される。逆に縦長に設定していた場合、グラフの横に回り込む文章の量が少なくなり、図2bのように表示される。制作者の意図通りに改行を指示するタグもないわけではないが、基本的にはどのような回り込み方をしても不都合が生じないような可塑的なレイアウトを想定しておく必要がある。
図2a |
図2b |
第3に、HTMLでは明朝体とかゴシック体といったフォントの指定ができない。どのフォントで表示されるかは読み手の設定に委ねられているからである。制作者が指定できるのは、大きさや斜体、強調、点滅表示といった基本属性にとどまる。
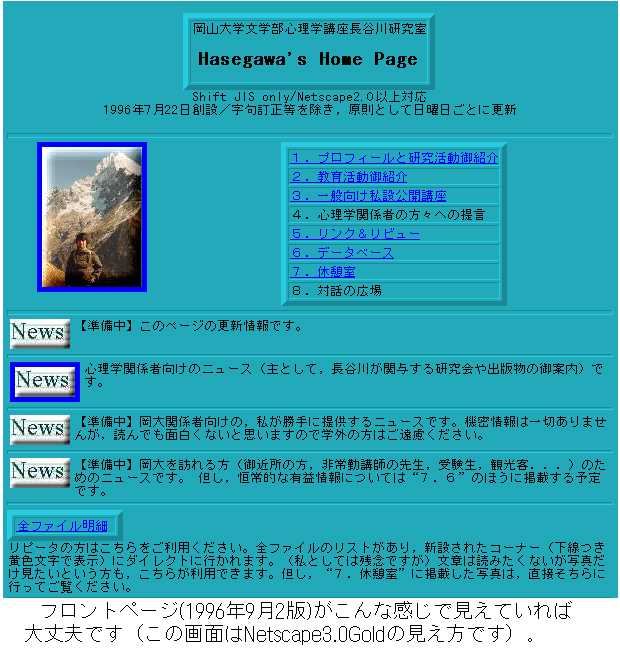
第4に、読み手が使用するブラウザによっても見え方が変わってくる。図3aは、筆者(長谷川)のホームページの最初の画面(1996年9月3日現在のフロントページ)をNetscape Navigator 3.0b7 Goldで表示しモノクロ印刷したものである。図3bは、Microsoft インターネットエクスプローラ初期バージョン、また図3cは、ジャストシステムのJust View ver1.1で表示したものである。制作者は図3aのような画面を想定しているが、ブラウザの種類によって、表機能や画像の配置に違いを生じることがわかる。なお、1996年8月よりインターネット上で無償配布が開始されたMicrosoft インターネットエクスプローラ3.0では、表枠の表示などに微妙な違いはあるものの図3aとほぼ同じ見え方になっている。
図3a |
図3b |
図3c |
第5に、HTML文書では写真やグラフなどの画像が自由に貼り込めるという点を強調しておこう。写真を取り込むには、プリントされた写真をスキャナで読み込む方法、ネガフィルムをフィルム専用スキャナで読み込む方法、デジタルカメラを利用する方法、ビデオ映像を取り込む方法などがある。グラフの場合には、専用の作図ソフトで作成した画像を用いる。いずれの場合も、画像ファイルは、jpg(ジェイペグ)またはgif(ジフ)といういずれかのフォーマットで保存する。このうち、jpgは24ビット色(1677万7216色)に対応した圧縮フォーマットであり、少ないサイズで鮮明さを損なわずにカラー画像を表示するのに適している。但し、線や文字を含む画像は圧縮の過程でにじみ見にくくなるという難点がある。いっぽう、gifは色数が256色までしか表示できないためカラー写真の表示には不向きではあるが、圧縮前と後で画質が変わらないので、色数の少ないグラフなどの表示に向いている。
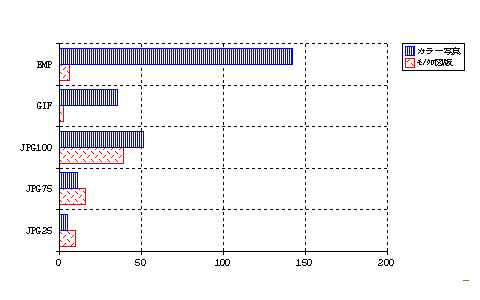
図4に、圧縮率をいろいろに変えた場合のjpgのサイズと、gif、及びWindowsの標準ファイル形式であるビットマップファイル(bmp)と比較した結果の一例を示す。カラー写真(161×301ピクセル、原画のサイズはおおむね6cm×10.5cm)の場合、bmpファイルでは142KBものサイズになるため、2HDフロッピーディスクは10枚も保存したら一杯になってしまうが、75%に圧縮した場合のjpgファイルのサイズはわずか10.7KBに縮小する。このサイズであれば2HDのフロッピーディスクに100枚以上を収納して、インターネットが接続できない研究機関に郵送することもできる。いっぽう、モノクロのグラフのように色数が少ない画像は、gifフォーマットを用いる。図4の下段の棒グラフは、220×220ピクセルの白背景に描かれた円グラフ図版のファイルサイズを比較したものであるが、jpgは色数の変更ができないのでかえってファイルサイズが大きくなってしまう。しかも特有の“にじみ”現象が出てしまう。これに対してbmpでは6.1KB、さらにこれをgifで保管することによって、画質を落とさずに2.1KBまで圧縮することができる。この他gifでは、簡単な動画を作ることもできる。
なお、jpgファイルの圧縮に伴う画質の低下の度合いを表示することは本稿のような印刷物上では不可能である。長谷川のホームページ(長谷川, 1996)上で
図4 |
第6に、声や音楽などのファイルを貼り込むこともできる。例えばHTML文書の中に <A HREF="music/music.mid">music.mid</A> と記述されていたとする。“music.mid”というmidi音楽ファイルが“music”というディレクトリの中に保管されていて、midiファイルを再生できるブラウザとパソコンがあれば、画面上の“music.mid”という部分をクリックするだけで、気軽に音楽を聴くことができる。あるいはJava Scriptを用いて < EMBED src="music/music.mid" width=51 height=15 controls=smallconsole autostart=true loop=true> と記述されていれば、そのHTML文書を開いた直後から音楽が流れ始め、ストップボタンを押さない限りは何度でも再生を繰り返すようになる。自分のパソコンのハードディスク内に音楽ファイルが保管されている場合にはファイル名をクリックするだけで再生ができるため、上記のようにわざわざHTMLに貼り込む必要はないかもしれない。しかし、音楽は著作権の問題から、簡単には複写できない場合が多い。音楽作品を論評するような時は、上記のようなローカルリンク(次章参照)ではなくインターネット上の配布元にリンクさせれば、不正コピーを回避することができる。例えば、配布元が仮に“http://www.okayama-u.ac.jp/music/”というサイトであった場合には、著作権者からの承諾を得た上で <A HREF="music/music.mid">music.mid</ A> の代わりに < A HREF="http://www.okayama-u.ac.jp/music/music.mid">music.mid</A >” というようにリンクを貼ればよい。
第7に、HTML文書はリンクが貼り込める。この特長は本稿の主題とも関連する決定的な違いであるので、次の章で詳しく論じることにしよう【補注】。
HTMLの最大の特長は、リンクスポットを作成できる点にあると言われる(Sachi, 1995, p.29)。これは、文書中の特定語句あるいはアイコンをクリックすると、別の画面に切り替えられる機能である。大きく分けて3通りのリンクがある。
第1に、同一文書内の指定箇所へのリンクである。これは例えば長大な論文の冒頭の目次にある“第3章”という語句をクリックすると、直ちに第3章に移動できるものである。この機能は、
目次部分に
<A HREF="#Sec3">3.第3章</a>
というタグをつけ、一方本文の第3章の見出し部分には
<LI><A NAME="Sec3">第3章</A>
というタグをつけることで実現できる。ワープロ文書内でも、マーク機能+ジャンプ機能を使えばよく似た操作をすることができるが、文書内の語句をクリックするのではなくワープロソフトのコマンドとして実行するため手間がかかる。
これは、ふつうローカルリンクと呼ばれている。例えば、自分のコンピュータのハードディスクのあるディレクトリにHTMLで記述された“長谷川(1996a)”という論文があり、その文中に引用された“長谷川(1991c)は...”という部分をクリックすると、被引用論文がただちに画面に表示されるような仕組みである。この機能を実現するには、まずハードディスク内に、2つの論文が、“Hasegawa1991c.HTML”、“Hasegawa1996a.HTML”というファイル名で保管されているものとし、“長谷川(1996a)”の引用記述のところを、 <A HREF="Hasegawa1991c.HTML">長谷川(1991c)</a>は... というようにタグをつければ事足りる。
なお、上の事例ではパソコンのハードディスクの場合をあげたが、同じ内容のファイルがWWWサーバのディスクに保管されており、外部からインターネット経由でこれを読み込んだ場合でも、まったく同じ移動が可能である。
インターネットに接続しているコンピュータでは、HTML文書中の語句などクリックすると、全く別のホームページに移動することができる。例えば、岡山太郎という人のホームページに掲載された論文に、上述と同じような“長谷川(1991c)は...”という引用記述があり、原著論文が
http://WWW.okayama-u.ac.jp/user/le/psycho/member/hase/h0u.HTML
というホームページに掲載されていたとする。
この場合、岡山太郎の論文の中で引用記述に
<A HREF="http://WWW.okayama-u.ac.jp/user/le/psycho/member/hase/h0u.HTML">長谷川(1991c)</a>は...
というタグをつけておけば、インターネット上の混雑や障害がない限りは、直ちに、長谷川のホームページに掲載された元の論文を参照することができるのである。
以上のリンク機能をもとに従来の印刷物とHTML文書との関係を集合の包含関係として表すと、図5のようになるだろう。この図では、それぞれの枠内に含まれる文書等は、その枠の外の特徴をすべて兼ね備えていることを意味している。すなわち、HTML文書は、いちばん外側の巻物と同じように目を通すこともできるし、目次だけを付加することもできる。従って、HTML文書である故に実現できないという要素は、読む方式の種類に限ってはない。但し、必ずブラウザを必要とするため、“畳の上で寝転がって読める”、“どこでも気軽に持ち運びができる”というような文庫本に含まれる要素が欠落する場合もある。
図5 |
本稿で特に強調したい点の1つは、HTMLとインターネットの独立性にある。HTMLで記述された文書は、インターネットに接続しなくても読むことができる。 例えば、筆者(長谷川)のホームページは、インターネット上では http://WWW.okayama-u.ac.jp/user/le/psycho/member/hase/h0u.HTML というURLを指定することでアクセスできるが、 筆者自身のパソコンのハードディスクCドライブ上にも同一のファイルがあり、このパソコンを使用する限りにおいては、 file:///C|/home/h0u.HTML(Netscape利用の場合。Microsoftインターネットエクスプローラ3.0では“C:\home\h0u.HTML”) と場所を指定するだけで全く同一の画面を見ることができる。その際、ローカルリンクはもとより、インターネット上の別のホームページへのジャンプも全く同じ操作で実現することもできる。特に自分のハードディスク内でのリンクは回線の混雑の影響を全く受けないので、瞬時に移動が可能である。
HTML文書とインターネットの関係を音楽に例えるならば、HTML文書は録音された音楽、インターネットはその再生手段の1つ、例えば有線TVで音楽を聴くというものと考えてよいだろう。有線TVで音楽を聴くには、まず有線TV会社と契約を結び、必要な工事を行わなければならない。しかし同じ音楽は、CDやカセットテープでも聴くことができる。その際の音質の違いは、パソコン本体の性能やブラウザの違いに例えることができるだろう。
そこで、例えば筆者のパソコンのハードディスク内にあるホームページ関連ファイルを何枚かのフロッピーディスクに保管して、電話さえつながらない離島の友人に送ったとしよう。もしそこで、電気が使え一定以上の性能のパソコンがあるならば、私の送ったフロッピーディスク上のファイルをハードディスクに丸ごとコピーしてブラウザソフトを起動すれば、インターネットに接続して見る場合と同じ内容を表示することができるのである。唯一の違いは、インターネット上の他のサイトへの移動ができないだけである。
前章で指摘したように、HTML文書はインターネットとは独立している。本章では、インターネットには一切接続しない状態のもとで、HTMLを用いてどのような知的資産が形成できるのかを考えることにしたい。
すでに述べたようにHTML文書では <IMG SRC="画像ファイル名"> というように文書中に画像ファイル名を指定するだけで写真やグラフを何枚でも自由に表示することができる。“何枚でも”と言っても無制限というわけではないが、パソコンの記憶媒体の容量を越えない限りは可能である。
印刷物を刊行する場合は、印刷上コストがかかるというだけの理由から、カラー写真はもちろん、モノクロの写真やグラフであっても掲載点数が厳しく制限されてきた。美学美術史の評論から、植物学、動物学、あるいは皮膚科の症例検討に至るまで、画像ぬきでは十分な議論ができない分野は山ほどあるだろう。また、印刷物は作りすぎれば資源の無駄になるし、不足したからといって再版を出すには手間がかかる。今後のHTMLの普及はこうした印刷上の制約や無駄を解消するので、画像を必要とする研究者間のコミュニケーションを確実にするばかりでなく、資源の節約にも一役買うことになるだろう。
このほか、HTMLは心理学の実験にも新しい可能性を開いた。従来、コンピュータで提示できる画像は比較的単純な幾何学図形に限られていた。最近の高性能のパソコンを用いて、HTMLで提示する画像を指定すれば、自然風景や人物写真などについての知覚、記憶、印象などについての実験を、特別のプログラミング技術を習得する必要なしに提示することができる。
ところで、画像というと、写真やグラフばかりが頭に浮かぶが、数式もひとつの画像として表示できる点も忘れてはならない。従来、ワープロで複雑な数式を表示するには“Tex”のような専用ソフトを利用するか、ワープロ内の“数式作成ツール”を起動してオブジェクトを作成する必要があった。しかし、HTMLで論文を書くのであれば、複雑な数式はみな白い紙に濃いペンで手書きし、これをスキャナで読み込んで画像ファイルにすればよい。文章と数式だけからなる論文を書くのであれば、2.2.に述べたように、単純なテキストファイルの文頭に<HTML><HEAD>、文末に、</BODY></HTML>、改行は<BR>を用い、数式部分を
<IMG SRC="数式画像ファイル名">
として挿入するだけで事足りるので、コンピュータの操作が比較的苦手と言われる純粋数学者でも難なく利用することができるだろう。
HTMLでは声や音楽、ビデオなどの貼り込みが簡単にできることもすでに述べた。“声”の貼付は、語学教材の作成、発音やイントネーションに関する言語学や人類学の研究に大いに役立つ。“音楽”の貼付は、音楽関係の評論や民俗学の研究に有効であろう。ビデオはファイルサイズが大きく転送時間などの関係から現状ではかなり制限があるが、動物行動学の資料やシミュレーション実験の実演などに役に立ちそうである。
第3章で詳しく述べたように、HTML文書は、巻物などと違って、行き先を自由自在に指定することのできる特長がある。
ここでは、主要なリンクスタイルと考えられるものを4通りに示し、その可能性を探ることにしたい。
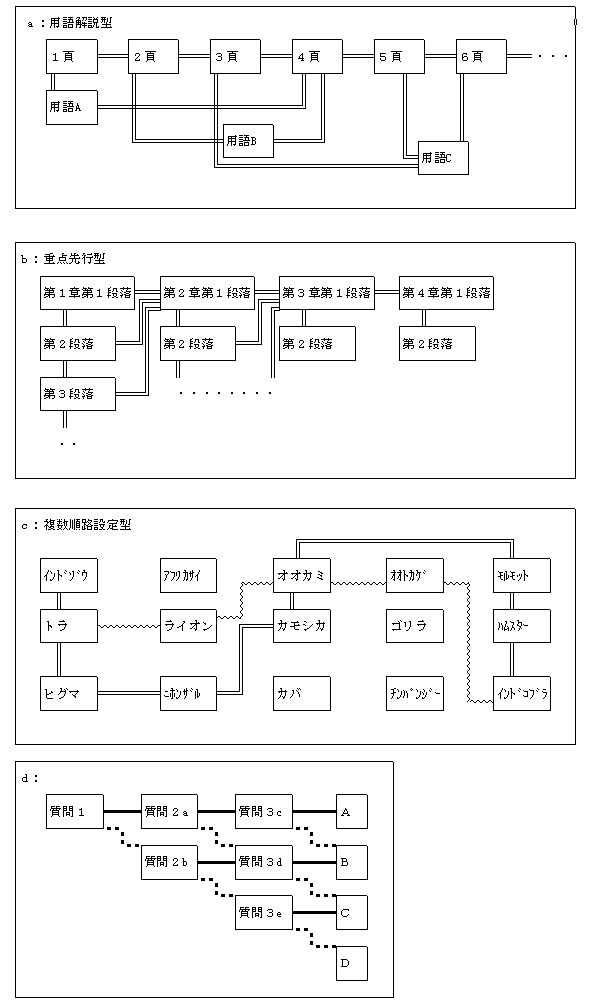
図6 |
最初にあげるリンクのパターンは、図6aに示すように、本文の頁を順にめくるようなリンクと、専門用語の解説に移動するリンクを組み合わせたものである。コンピュータソフトのヘルプファイルなどは大概この形式になっている。
専門用語が多く含まれた解説書などでは、用語の意味がわからずに無駄な時間を費やすことが多い。しかし、だからといって、ページの脚注にゴタゴタと用語解説を付け加えたのでは、初心者は喜ぶがある程度知識を身につけた読者には冗長となる。そこで、専門用語をクリックした時だけ解説が表示されるようにすれば、みずからのレベルに応じて読み進むことができるので、読者対象を初心者から専門家まで広げることができる。
このパターンは、他に、文芸評論などにおける注釈、語学教材における音声提示(単語をクリックすると正しい発音が聞こえる)などさまざまな活用が可能である。
膨大な数の論文を読む必要がある研究者にとっては、個々の論文を推理小説を読むように初めから終わりまで読み通す余裕はない。とにかく、その論文が“どういう目的で、何を対象とし、どういう方法を用いて、何がわかったのか”を知ることが大切である。もし、自分のテーマにあまり関係ないとわかれば読むのを打ち切る。非常に関係が深いものだけを精読すればよいのである。
新聞記事も同じであり、忙しい人は見出しと最初の段落だけ読んで何が起こったのかを知る。それが自分にとって重要であれば、次の段落に読む進む。
このような構成をHTMLで実現したものが図6bである。このようなリンク構成にすれば否応なしに重点先行型の構成をせざるをえないので、学生の論文執筆指導にも活用できそうである。
例えば、動物園を回るとき、図6cに示すように、“アジア地域に生息する動物を見る(二重線でつながれたコース)”とか、“肉食動物だけを見る(波線でつながれたコース)”といったように、見学者の興味に応じたコースを設定することができる。現実の動物園では、飼育舎間の距離などによって理想的なコースの設定は難しいが、HTML文書で記述された解説書であれば、どのようなコースも自由自在に設定できる。
各文書が質問形式になっており、読み手の回答がYesかNoかによってリンク先を変えるようなスタイルである。例えば、将来肺癌になるかどうかの危険性を診断するテストとして、図6dのような構成を考える。質問1では“あなたはタバコを吸ったことがあるか”、質問2aでは“あなたは今もタバコを吸っているか”、質問2bでは“あなたの家族にタバコを吸う人がいるか”というような文章を書き込む。そして、それぞれYesと答えれば太実線で示すリンクによって右横の質問に移動し、Noと答えれば太破線で示すリンクによって右下の質問に移動する。最終的にはいちばん右のA,B,C,Dの部分の危険度と注意書を示す文書にたどり着く。これは、Yesと答えるごとに1点、Noと答えた場合は0点が加算された場合の合計点による分類と一致している。
以上、図6に代表的と思われるスタイルを4点あげたが、このほかにもさまざまなリンクの組み方が考えられる。
例えば、迷路の各分岐点を1つずつの文書に見立て、曲がる方向をクリックすると次の分岐点に到達するというようなアドベンチャーゲーム風の繋ぎ方をすることもできる。迷路を森の中に置き換えて、自然観察教材を作れば、子供は自分の好きなルートをたどって動物や植物の説明を読むことができるので、“先生の後を金魚の糞のようにくっついていく”ような堅苦しい勉強から“自由に森の中を飛び回る”学習をすることができるだろう。同じスタイルは、英会話の勉強にも活用できる。テキストを順番に学ぶのではなく、擬似的に海外旅行をしながら自分の行きたい場面に次々と移動しながら必要な表現を学ぶこともできるのである。
道に迷った時に自分で別のルートを探さなければならないような迷路型とは反対に、多様な問題解決法のそれぞれにヒントを与えて最終解決に導くようなスタイルも考えられる。例えば、ある数学の問題を与えた時に、とりあえず特定の公式を利用する方法を選ぶか、背理法で解くか、数学的帰納法を用いるか、図形に置き換えて幾何的に解くかなどの進路を選ばせ、どれを選んでもそれに見合ったヒントを提示して解決に導くというような教材が考えられる。
最後に、以上に紹介したスタイルは、いずれも“人に読んでもらう”文書、つまり読者の便宜をはかったリンクのスタイルであったが、自分だけが利用する文献目録、備忘録、読書ノート、論文概略メモ、写真、新聞記事、雑資料などをすべて“非公開ホームページ”の中で管理することもたいへん有用であると思う。“非公開”が前提であるから、大学のWWW用ワークステーションにファイルを転送する必要はない。自分のパソコンのハードディスクやZIPやMOなどの大容量可搬記憶媒体に保管しておけばよいのである。画像や音声が取り込めるぶんだけ、市販のデータベースソフトを利用する場合よりはるかに手軽で柔軟性にとんだデータベースが構築できるはずである。
インターネットとの接続を前提としない状況のもとでのHTMLの活用の意義を強調するという本稿の目的からは外れるが、最後に、インターネットを研究活動に利用する上での若干の問題点についても指摘しておくことにしたい。
インターネットを利用することの基本的意義は、情報発信と情報収集の2点にある。前者は、研究者が大学のWWWサーバに自分のホームページを開設し、研究活動の紹介や情報の提供を行うこと、後者は、他の研究機関などのホームページを渉猟することによって、必要な情報を取得することである。しかし、本稿の提出締切日にあたる1996年9月上旬の時点では、いずれの利用可能性もはなはだ不十分な状況にあると言わざるを得ない。
まず、前者について現状を把握してみると、実際に研究室にパソコンを設置し、学内LANを通じて情報を提供している研究者はきわめて少ないと言わざるを得ない。一例として、表2に1996年9月上旬時点岡山大学全体の日本語ホームページ開設状況を示すが、文法経3学部で自らの研究業績を紹介している教官は9名のみであり、また理系学部でも医学部や歯学部はきわめて少ない現状にあることがわかる。また、岡山大学全体を紹介した部分と言えば、事務局のページを開いたところに“沿革”と“組織図”があるだけで、外国の大学の豊富なホームページに比べると貧弱さは否めない。しかも、この“沿革”と“組織図”は、出版物の『岡山大学概要』の該当頁をそのままスキャナで読み込んでGIFファイル化したものらしく、“沿革”が807KB、“組織図”が770KBというように、いずれも2HDフロッピーディスクの容量の半分を越える巨大サイズになっており、個人が電話回線を通じて参照できるような代物ではないことがわかった。
| 学部 | 開設状況 |
|---|---|
| 文学部 | 14大講座中5講座。教官は4名のみ |
| 教育学部 | 25教室中7教室。 |
| 法学部 | 未開設 |
| 経済学部 | 教官は5名のみ。 |
| 理学部 | 31教室中、21教室。 |
| 医学部 | 基礎医学系17講座中5講座。 |
| 歯学部 | 基礎系18講座中1講座。 |
| 薬学部 | 16講座中※、13講座。但し、うち6講座は半頁程度の紹介文のみ。 |
| 工学部 | 6学科中5学科。独立サーバも多数。内容は本格的なものから紹介文程度まで色々。 |
| 環境理工学部 | 12講座中3講座。 |
| 農学部 | 学部紹介文のみ |
いっぽう全国の心理学研究室の開設状況を筑波大学の磯部(1996)の“日本のインターネット心理学関連情報”(1996年9月7日更新分)を参照して数え上げてみると、主見出しの項目数で全国で88の機関・研究室がホームページを開設していることがわかった。しかし、その中にはスタッフの名前だけを紹介した簡素なものもあり、個々人が自分のオリジナルの情報を提供しているところはそう多くはないように見受けられる。
また、心理学の研究室で、いわゆる検索サイトに登録しているところはきわめて少ない。表3に、主要な登録型検索サイトにおいて“心理学”を検索語とした場合のヒット件数を示す。大学あるいは研究所と推定される件数は、10件にも満たず、心理学研究者以外が一般の検索サイトを利用して心理学の情報を求めても現状では満足のいく資料が得られないのではないかと危惧される。
| 検索サイト略称および URL(“http://”は省略した) | “心理学” ヒット数 総数 | そのうち 大学・ 研究所 | 朝8-9時 接続 | 検索 | 15時(上) 17時 接続 | 検索 |
|---|---|---|---|---|---|---|
| Yahoo! Japan | _____ 25 | _____ 7 | OK | OK | OK | OK |
| www.yahoo.co.jp/ | _____ | _____ | _____ | _____ | 40sec | 10sec |
| NTT DIRECTORY InfoBee | _____ 43 | _____ 8 | OK | OK | 215sec | 240sec |
| navi.ntt.jp/ | _____ | _____ | _____ | _____ | 95sec | 65sec |
| Hole-in-One | _____ 7 | _____ 2 | OK | 5sec | 215sec | 25sec |
| 207.82.104.200/ | _____ | _____ | _____ | _____ | 20sec | 15sec |
| NetPlaza | _____ 17 | _____ 5 | OK | OK | 35sec | 30sec |
| netplaza.biglobe.or.jp/ | _____ | _____ | _____ | _____ | 10sec | 5sec |
| InfoNavigator | _____ 28 | _____ 3 | OK | OK | OK | OK |
| infonavi.infoweb.or.jp/ | _____ | _____ | _____ | _____ | OK | OK |
| JapanSearchEngine | _____ 8 | _____ 1 | OK | OK | 50sec | 30sec※ |
| www8.pageweb.sinfony.ad.jp/jse/ | _____ | _____ | _____ | _____ | 25sec | 25sec |
| Net Office Nakai | _____ 2 | _____ 1 | 30sec | 25sec | 335sec | OK |
| www.kyoto-net.com/link/ | _____ | _____ | _____ | _____ | 415sec | 5sec |
以上指摘したように現状では、研究者の情報発信機能としてのインターネットは、日本国内ではまだ完成途上にあると言わざるを得ない。
研究者からの情報発信が不十分である以上、収集する側が満足できる資料を得られないのは必然である。しかし、これ以外にも、インターネットの利用は現状ではいくつかの問題を抱えている。
まず、混雑のため、目的とするサイトへの接続が思うようにできないという問題がある。接続が完了するまでの時間は曜日や時間帯によって著しく異なるのでここで信頼できる数値を示すことはできないが、表3の右端に示すように、例えば国内の検索サイトに接続しようとしても、平日の午後にはなかなか接続ができず、ダウンロードサイトのような場合には受信完了まで何十分もかかるという場合がある。筆者の研究室のように学内LANのイーサーネットケーブルが研究室内まで敷設され、独自のIPアドレスのもとでインターネットに直結できるような環境でさえこの現状であることを考えれば、主として自宅の書斎で研究をすすめる教官が電話回線で接続するような場合には、さらに長大な時間と相当の電話料金を支払うはめになるものと推測される。
表3に示した登録型検索サイトとは別に、ロボット型検索システム(国内であれば、“.jp”ドメイン内に存在するWWWサーバー上にある文書の検索を目的としたサーチ エンジン)というものもある。これは、アクセス可能なホームページであれば、制作者の登録の意志と無関係にそのタイトルや文書内容が検索される。たとえば、ODINという試験運用中のロボット検索サイト(http://kichijiro.c.u-tokyo.ac.jp/odin/)で“心理学”を検索語として入力すると、1996年9月9日現在で、433ものURLがヒットした。このように情報量が莫大なものになってくると、その中からどうやって自分が必要とするものだけを取得するのかという問題が生じてくる。武田(1996)によれば、情報収集には、上に述べた情報検索のほかに、情報フィルタリングや漠然とした目標しかもたないときにも情報収集を可能にするような“ブラウジング”といった方法がある。この論文には、情報分類、情報抽出、情報組織化の方法も紹介されており、今後の発展が期待される。
現時点では、心理学者が開設したホームページのなかから有用なものを知人からのEメイルで教えてもらい、これをブックマークあるいはインターネットショートカットに登録しておき、ここを起点として目的のサイトへジャンプするというのが現実的で確実な方法であるように思われる。
情報収集機能とはやや異なるが、特定のメンバーの中で意見を交換するメイリングリストというのも活用されている。メイリングリストとは、登録メンバーの発言がメンバー全員にEメイルとして配信されるようなシステムである。心理学関係であれば、筆者が参画したものとして心理学研究の基礎(Foundations of Psychological Research, 略称FPR)というものがある。これは新潟国際情報大学の松井孝雄氏が管理しており(松井, 1996)、1996年1月6日から同年8月20日までの間に250件あまりの発言がなされている。ただ、この方法であると、議論が活発化した時など、毎日数十件ものメイルが配信されてくる可能性があり、知らない打ちにメイルボックスが満杯になってしまう危険性もある。
誰でも登録せずに議論や質問ができる場としてはネットニュースが知られている。しかし、参加者が限定されていないため、マニアのような人からの言葉尻を捉えた攻撃的発言によって議論がかき回されたり、また専門家と素人の間の認識の違いによって議論がかみ合わなくなるなどの問題があり、研究のための情報収集にはあまり適していないように思われる。
WWW(World Wide Web)には“世界に張り巡らされたクモの巣”という意味がある。研究者はその網を伝わって、自由にホームページ間を渉猟することができるはずである。しかし、情報が莫大な量にのぼるなかで、個々のホームページに指定されたリンク先にジャンプしていく行動は、ともすれば受け身的にならざるをえない。堀(1996)は、このような“自由”の喪失について次のように述べている。
研究目的でインターネットを利用する場合には、張り巡らされたリンクに流されることなく、能動的主体的に情報収集につとめる姿勢が必要であると思う。WWW(World-Wide Web)というものがある。ご存知のようにインターネットの情報流通形態の一つであり、いわゆるハイパーテキストとマルチメディアをネットワーク上で実現したメディアとして脚光を浴びている。私自身は、実物に触れる1年ほど前からその存在は耳にしており、使用感も(従来のGUIの類推などから)大体の見当はつけていた。ところが実際にそれに接してみると、これまでのネットワーク上での情報検索とはすっかり様相を変えた、ほとんど拍子抜けするような「たやすさ」、扱える情報の「多彩さ」などに、ちょっとした興奮をおぼえずにはいられなかった。【一部略】
何時間か没頭してその世界で遊んだ私は、しかしこのような最初の高ぶりが鎮まるにつれて、ある意味で関連する二つの、どちらかといえば否定的な印象を持ちはじめた。一つは、情報のリンクが“world-wide”であることが、つまり巨大な物理空間に点在する情報群を結合した壮大なシステムであることがほとんどたちどころに意識されなくなるということであり、もう一つは、情報の探索が、その見かけ上の随意性にもかかわらず、実際には情報リンクの構築者によってあらかじめ「仕組まれた」ルートから一歩も外に踏み出せないことからくる一種の息苦しさであった。
【中途略】
WWWは世界をおおう情報の網(web)のはずであった。しかしそれは同時に、情報への接近のあり方を(久保田氏のことばを借りるなら、<手探り>を)拘束する「網」、あるいは、われわれの自由な行動を捕捉する「クモの巣」にもなりうる。WWWに限らず、次々に開発されてくる新しい「情報システム」は、システムの目的に応じた効率や簡便性と引き替えに、(かつては存在したように思われる)「自由」をわれわれから奪いつつあるのかもしれない。
【以下略】
本稿で最も強調したいことは、インターネットへの接続とは一切無関係な環境にあっても、HTMLで記述されたハイパーテキストが新しい知的資産の形成にきわめて有効であるという点にある。HTML文書は、比較的小さいサイズの文書をリンクで関連づけることによって構成されるため、あるいは、“HTMLでは断片的な知識の固まりしか提供することができない”といった疑問が出るかもしれない。しかし、図5に示したように、HTMLは、巻物や書籍で可能な機能に画像貼付やリンクといった新しい機能を付加したものである。必要がなければその機能は使わなくてもよいので、HTMLで記述することによって何かが失われるということはない。しいて言えば、表示にコンピュータを必要とするため、旅行先や公園のベンチでは読めないという問題がある。しかし、すでにCD-ROM版の辞書や書籍を再生するための“電子ブックプレーヤー”が市販されていることを考えれば、いずれ、フルカラー対応の液晶パネルのついたHTMLプレーヤーが普及するようになるかもしれない。そこまでして、公園のベンチで文書を読む必要があるかどうかは別問題であるが。
最後に、HTML文書と研究論文の関係について考えてみることにしたい。湯田(1995)は、“インターネットにおける心理学関連情報”というタイトルの発表の中で、SGMLによる論文入稿システム、物理学・数学などの分野では学術論文が雑誌に掲載可となった段階で,プレプリントを同じ分野の研究者に配布するという習慣(プレプリント・アーカイブ)、従来の印刷物による論文とは別に,はじめからネットワークによる流通を目指した電子ジャーナル(Electronic Journal),オンライン・ジャーナル(Online Journal)などの形態を紹介している。これらはいずれも、論文は最終的に印刷物あるいはそれと同等の表示が可能な範囲のメディアとして発表されることを前提にしているようだ。しかし、今後印刷物としての学術雑誌や書籍に代わって、HTMLなどのハイパーテキスト論文がインターネットを通じて発表されたりCD-ROM化されて保管されたりする可能性も出てくる。これには、研究の実施から成果の公表までの時間を大幅に早め、またコストはほとんどかからないというメリットがある。
上に述べたような新しい媒体で“刊行”されるようになった時には、論文の価値とはどういうものを言うのであろうか。従来、教官の採用人事の審査などでは、その候補の論文を評価する基準の1つとして、それがレフェリー付きの学術雑誌に投稿されたものであるか、その雑誌の評価は世界的みてどうか、といった点が考慮されることがあった。しかし、自分のホームページを発信起点として論文を発表していくぶんには、レフェリーのお墨付きをもらう必要はない。そのかわりに、その論文がどれだけ別の研究に引用され活かされたかということが、Eメイルやメイリングリストを通じて刻々と伝わってくるようになる。つまり、従来のように編集者が依頼した2名ないし3名のレビューワーの評価によって掲載の可否や修正が決まるかわりに、論文の読者すべてが評価意見を述べることができるようになるのである。
研究分野によっては、その時代の研究者には殆ど支持されなかったが100年後に高い評価を受けるようになった論文とか、それを理解できる数学者は世界中に10人もいないと言われるような定理の証明を記した論文などもあるかもしれないが、人文・社会・自然にかかわる科学論文は、本来は他者に読んでもらい他者に有益な情報を提供することを目的に執筆されるべきものである。一流雑誌に掲載されているかどうかは採用人事の基準にはなるかもしれないが、論文の本質的な価値を決めるものではない。著作権に十分に配慮しつつも、今後さらに、多様なメディアを活用した研究成果の公表されていくことに期待していきたい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}